1. 카프카 디자인의 특징
1-1. 분산 시스템
분산 시스템
같은 역할을 하는 여러 대의 서버로 이루어진 서버 그룹을 말한다.
분산 시스템의 장점
- 단일 시스템보다 더 높은 성능을 얻을 수 있다.
- 하나의 서버에서 CPU 사용율이 너무 높다고 판단하면 서버를 한 대 추가하여 CPU 사용율을 줄일 수 있다.
- 하나의 서버 또는 노드가 장애가 발생해도 다른 서버 및 노드에서 대신 처리한다.
- 시스템 확장에 용이하다.
1-2. 페이지 캐시
페이지 캐시란 OS 가 애플리케이션이 사용하고 남은 물리적 메모리 중 일부를 페이지 캐시로 유지한다. 페이지 캐시를 사용하면 디스크를 사용하지 않고 읽어 들어서 속도가 빠르다.
카프카는 OS의 이런 페이지 캐시를 사용하여 처리 성능을 향상시켰다.
1-3. 배치 전송 처리
IO 작업이 많이 일어나면 네트워크 왕복의 오버헤드가 발생하여 이 또한 속도를 저하시킨다. 카프카는 여러 작은 IO 작업 단위를 묶어서 한 번에 처리할 수 있는 기능을 지원한다.
그래서 네트워크 비용을 적게 사용하여 처리 성능을 향상시켰다.
2. 카프카 데이터 모델
토픽과 파티션이라는 데이터 모델 덕분에 카프카는 고성능, 고가용성 애플리케이션이 가능했다.
2-1. 토픽
토픽은 데이터를 구분 지어 저장하는 저장소 개념이다. 데이터들의 카테고리에 따라 분류되어 저장될 수 있다.
2-2. 파티션
메시지를 더 빠르게 전송하기 위해 토픽을 분할한 것이다.
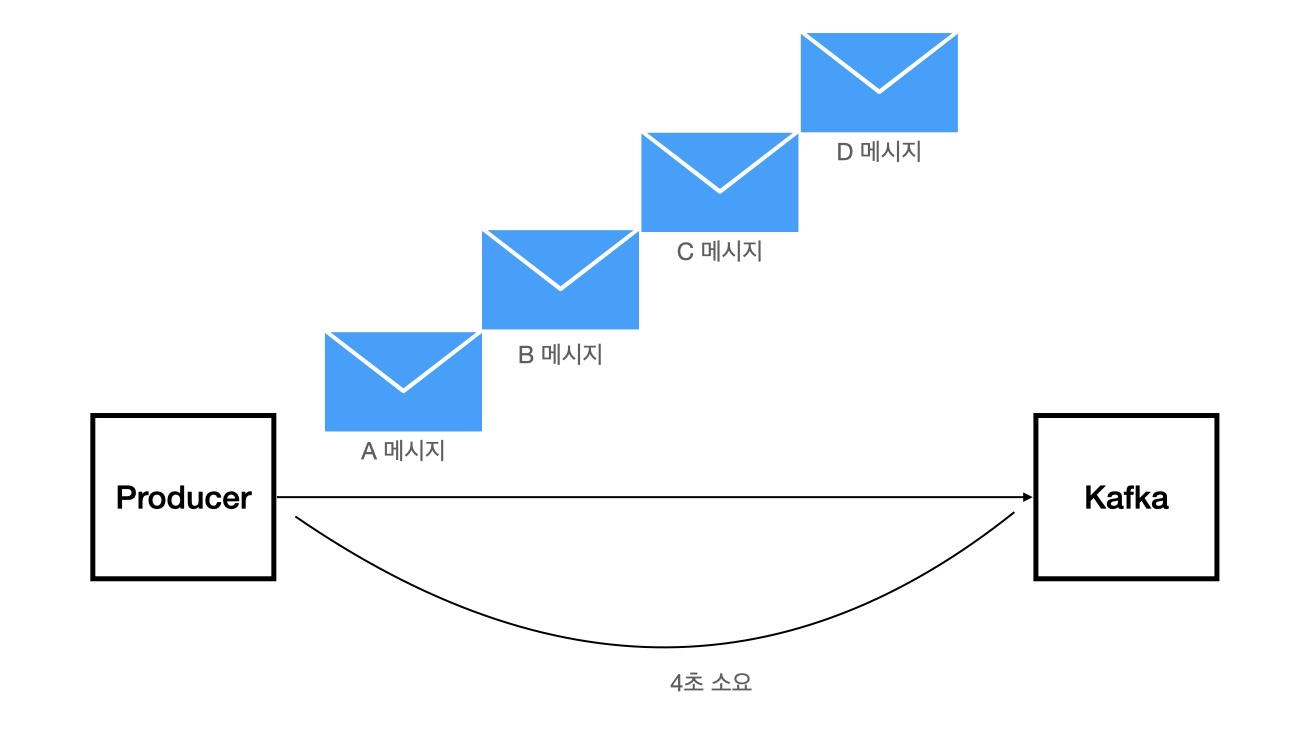
한 개의 파티션에 하나의 메시지를 보내는 데 1초 걸리는 프로듀서가 있다고 했을 때, 4개의 메시지를 보내려면 4초의 시간이 걸린다. 더 빠르게 메시지를 보내고 싶어서 프로듀서만 늘린다면 효율적으로 시간이 단축되지 않을 것이다.
왜냐하면 메시징 큐 시스템은 순서 보장이 되어야 하기 때문에, 카프카는 하나의 파티션에 대해서는 메시지 순서가 보장이 된다. 그렇기 때문에 하나의 메시지를 처리하고 난 후에 다른 메시지를 처리하기 때문에 효율적인 속도 향상이 어렵다.
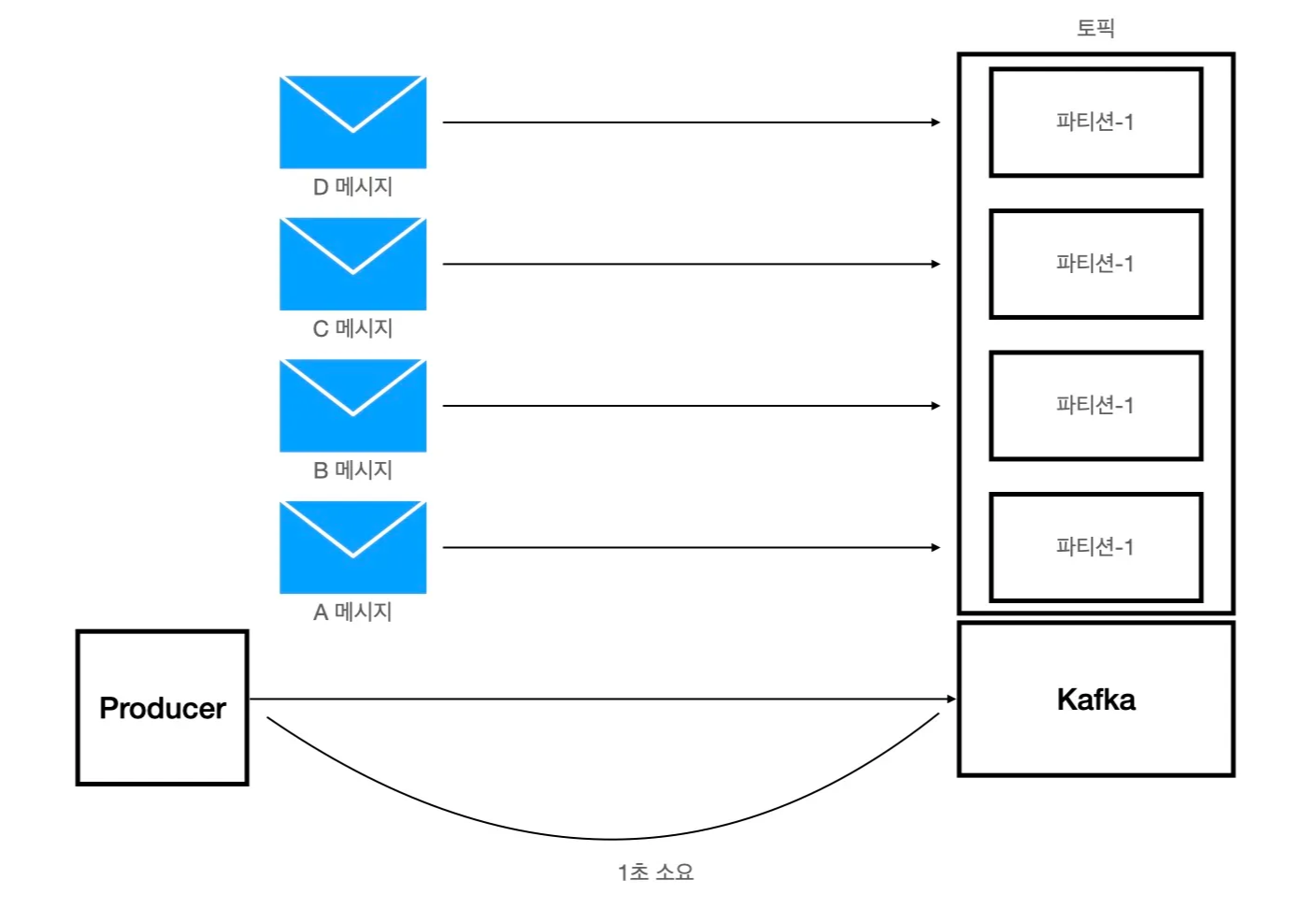
그렇기 때문에 프로듀서 개수뿐만 아니라 파티션 개수도 늘려서 동시에 각각의 파티션에 전송하면 속도 향상을 시킬 수 있다. 예를 들어, 프로듀서와 파티션을 각각 4개씩 늘린다면 4개의 메시지를 전송하는 데에 1초로 전송 속도를 향상시킬 수 있다.
파티션 수를 무조건 늘리면 생길 수 있는 단점
파일 핸들러 낭비
각 파티션에 저장되는 데이터마다 2개의 파일(인덱스 관련 파일, 실제 데이터 관련 파일)을 만들게 되고, 카프카는 이 파일 핸들을 열게 된다. 그래서 파티션 수가 많을수록 카프카가 여는 파일 핸들도 많아지게 되어 리소스 낭비로 이어질 수 있다.
장애 복구 시간 증가
카프카는 높은 가용성을 보장하기 위해 리플리케이션을 지원한다. 파티션마다 리플리케이션이 동작하게 되며, 여러 개의 블로커 중 하나는 파티션의 리더이고, 나머지는 팔로워가 된다.
리더 파티션이 있는 브로커가 다운 시에 팔로우 파티션 중 하나가 리더 파티션이 된다. 이를 수행하는 것이 컨트롤러 블로커이다. 컨트롤러 블로커는 클러스터 내에서 하나만 존재한다.
만약에, 컨트롤러 블로커가 다운이 된다면 클러스터 내의 다른 블로커가 컨트롤러 역할을 수행하게 된다.
그렇기 때문에 하나의 블로커에 많은 파티션이 있게 됐을 때, 그중 리더 파티션을 다른 블로커의 팔로우 파티션으로 이동하여 장애를 복구하는 시간이 증가하게 된다.
파티션 수는 줄이는 것은 불가능하기 때문에 무조건 많이 늘리기보다는 목표 처리치를 가지고 운영해 보면서 조절하는 과정이 필요하다.
2-3. 오프셋과 메시지 순서
오프셋은 각 파티션마다 메시지가 저장되는 위치를 오프셋이라고 부른다. 오프셋은 파티션 내에서 유일하고 순차적으로 증가하는 64비트 정수이다.
카프카 컨슈머는 같은 파티션 내에서 오프셋이 저장된 순서대로 컨슘 해간다. 0, 1, 2 … 이렇게 먼저 저장된 메시지는 먼저 컨슘 된다. 다만 오프셋은 파티션 내에서 유니크하기 때문에 다른 파티션끼리는 메시지 순서가 보장되지 않는다.
3. 카프카의 고가용성과 리플리케이션
카프카는 높은 가용성을 제공하기 위해 파티션 리플리케이션 기능을 지원한다.
3-1. 리플리케이션 팩터와 리더, 팔로워의 역할
카프카는 높은 가용성을 제공하기 위해서 리플리케이션을 지원한다. 여러 서버(이하 브로커)에 데이터를 저장 및 복제하는 등의 방법이다.
리플리케이션할 브로커 숫자는 리플리케이션 팩터로 설정할 수 있다.
# vi /usr/local/kafka/config/server.properties
default.replication.factor = 3
원본 데이터는 리더에 저장되고, 팔로워에 그 데이터가 복제되어 저장된다. 기본적으로 프로듀서, 컨슈머는 리더 파티션에 읽고 쓴다. 팔로워 파티션에서는 복제 저장만 하게 된다.
이렇게 함으로써 하나의 리더 파티션이 죽더라고, 다른 팔로워 파티션이 리더가 되게 되고, 데이터를 이어서 프로듀스, 컨슘 할 수 있게 된다.
하지만, 단점도 존재한다. 데이터가 복제되어 저장되기 때문에 원래 사이즈의 리플리케이션 팩터만큼 곱해진 메모리를 사용하게 되고, 리더와 팔로워 사이에 데이터 정합성을 위해 보정처리를 하기 때문에 그에 인한 리소스도 사용하게 된다.
그래서 파티션의 개수와 마찬가지로 무작정 늘리지 않고 운영해 보면서 적정한 사이즈를 찾는 것이 중요하다.
3-2. 리더와 팔로워의 관리
리더 파티션에는 데이터가 저장된다. 팔로워 파티션에는 리더 파티션에 있는 데이터를 동기화한다.
만약에 팔로워가 리더가 데이터 정합성이 맞지 않게 되면 큰 문제가 발생할 수 있다. 왜냐하면 데이터 정합성이 맞지 않은 상태에서 리더가 다운되어 버리면 팔로워가 데이터가 누락된 채로 리더가 되기 때문이다.
그래서 카프카는 ISR(In Sync Replica)라는 개념을 도입하여, 데이터 정합성이 깨지지 않도록 했다.

Topic01:
- 파티션 수 2, 리플리케이션 팩터는 3이다. 리더 1개와 팔로워 2개로 구성되고, 하나의 ISR로 묶인다.
Topic02:
- 파티션 수 2, 리플리케이션 팩터는 3이다. 리더 1개와 팔로워 1개로 구성되고, 하나의 ISR로 묶인다.
ISR 은 리더와 팔로워가 동기화가 잘 되어있는 그룹이다. 팔로워는 주기적으로 리더에서 데이터를 동기화한다. 리더는 설정된 값 동안에 팔로워에게서 동기화 요청이 오지 않으면 그 팔로워를 ISR에서 내쫓는다.
그래서 리더가 죽으면 같은 ISR에 있는 팔로워가 데이터가 누락 없이 리더가 된다.
4. 카프카에서 사용하는 주키퍼 지노드 역할
controller
- 경로: /{주키퍼 지노드 루트}/controller
카프카 클러스터의 컨트롤러 브로커의 정보를 확인할 수 있다.
브로커가 다운돼서 리더가 변경이 됐을 때, 리더 선출 작업이 필요하다. 컨트롤러 브로커는 이 역할 수행한다.
컨트롤러가 브로커 레벨에서 브로커 실패를 확인하게 되면 영향받는 모든 파티션에 대해 리더 변경을 책임진다. 만약에, 컨트롤러 브로커가 다운된다면 클러스터 내 다른 브로커가 컨트롤러 역할을 맡게 된다.
brokers
- 경로: /{주키퍼 지노드 루트}/brokers
브로커들 정보를 확인할 수 있다.
/brokers/ids: 임시 노드에 브로커 config에서 수정한 id를 확인할 수 있다.
/brokers/topics/{토픽 이름}: 토픽의 파티션 수, ISR 구성 정보, 리더 정보 등을 확인할 수 있다.
consumers
- 경로: /{주키퍼 지노드 루트}/consumers
컨슈머들이 각각의 파티션에 대해 어느 offset까지 읽었는지 확인할 수 있다.
config
- 경로: /{주키퍼 지노드 루트}/config
토픽의 상세 설정 정보를 확인할 수 있다.
ref
- 카프카, 데이터 플랫폼의 최강자 / 고승범 저 공용준 공저
'카프카' 카테고리의 다른 글
| 카프카 컨슈머 (0) | 2025.04.29 |
|---|---|
| 카프카 프로듀서 (0) | 2025.03.20 |
| 카프카란 무엇인가? (0) | 2024.12.27 |


